Runter mit dem Pseudoausschuss
Retrofit von Vision-Systemen durch konsistente Datensätze
Andreas Breyer, Vision Communications
Klassische regelbasierte Bildverarbeitungssysteme können ebenso wie einfache, auf Anomalie-Erkennung trainierte KI-Systeme meist nicht mit Produktionsvarianz umgehen. Reflektierende oder nur geringfügig unterschiedlich produzierte Teile führen dann zu hohem Pseudoausschuss und verursachen erhebliche Zusatzkosten. Dabei lässt sich der Umgang mit Produktionsvarianz auch in vorhandenen Systemen mit den passenden Software-Upgrades deutlich verbessern.
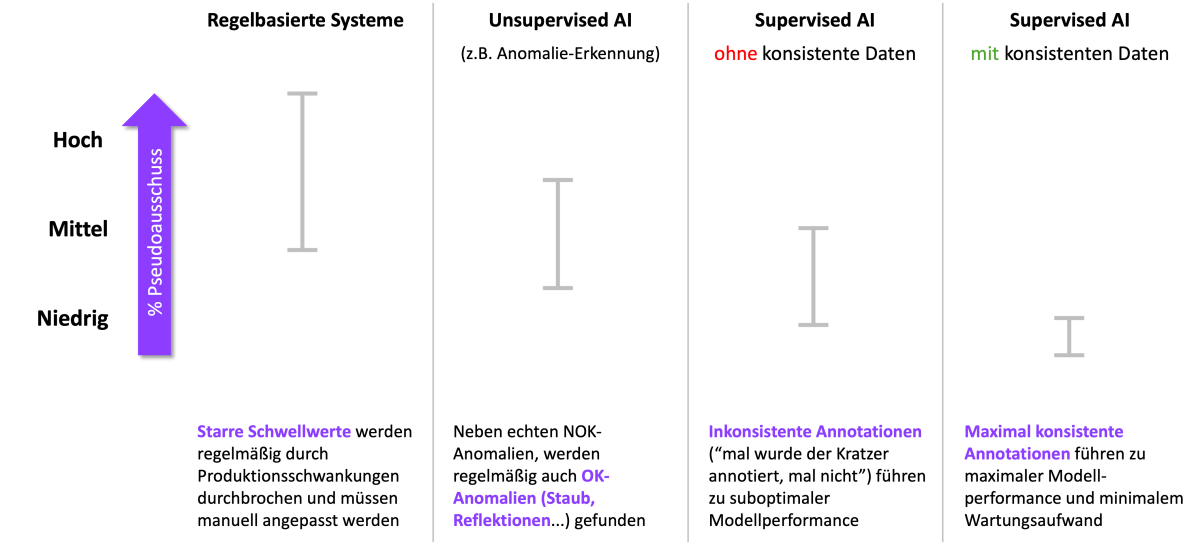
Noch basieren viele der installierten Bildverarbeitungssysteme zur Qualitätskontrolle in Produktionsanlagen auf regelbasierten Systemen. Sie sind zuverlässig darin, eindeutige Gutteile und klar definierten Ausschuss zu erkennen und entsprechend zu sortieren. Voraussetzung dafür sind jedoch konstant optimale Bedingungen, wie etwa die Beleuchtung und die Form der zu prüfenden Teile. Auch kleine Veränderungen in den aufgenommenen Bildern sind ein großes Problem für klassische Vision-Systeme. Diese Veränderungen können zum Beispiel durch Produktionsschwankungen oder Umgebungsveränderungen, wie Beleuchtung, Reflektionseigenschaften, etc., auftreten. Da klassische Bildverarbeitungssysteme mit starren Schwellwerten arbeiten, führen solche Veränderungen fast immer zu signifikant höheren Falschrückweisungsraten. In der Folge sinkt die Erkennungszuverlässigkeit für Gutteile, der Pseudoausschuss wächst und es entstehen zusätzliche Kosten. Natürlich lassen sich diese Pseudoausschussprobleme beheben, indem die Schwellwerte angepasst werden. Sind Anpassungen allerdings regelmäßig notwendig, wirkt sich dies negativ auf die Wartungskosten aus.
Anomalieerkennung mit KI reicht nicht
Varianzen im „OK-Bereich“ sind daher mit Vision-Systemen, die auf Schwellwerten basieren, nur dadurch abzubilden, dass die Schwellwerte für jede Eventualität angepasst werden. Das erfordert jedes Mal einen Arbeitsaufwand und ist zudem fehleranfällig, etwa wenn von Mitarbeitern nicht rechtzeitig erkannt wird, dass sie den Schwellwert anpassen müssen. Das legt den Gedanken nahe, die Leistung mit KI-basierten Systemen zu erhöhen. Doch auch hier lohnt sich ein genauerer Blick. Je nachdem welcher KI-Ansatz verfolgt wird, können Pseudoausschussrate und Wartungsaufwand mitunter gleich hoch sein wie bei einem regelbasierten Vision-System. Einfache unüberwachte KI-Modelle lernen lediglich, wie Gutteile aussehen, und deklarieren daher jede Abweichung in der Qualitätskontrolle als Ausschuss. Daher birgt auch dieser Ansatz das Risiko, dass kleine, tolerierbare Anomalien – sogenannte Gut-Anomalien – aussortiert werden. Im Vergleich zu regelbasierten Vision-Systemen lassen sich KI-Modelle aber viel einfacher in der Varianz erweitern. So müssen beispielsweise bei Farbvarianten von Bauteilen oder bei veränderter Beleuchtung nicht etwa Algorithmen neu geschrieben oder Schwellwerte angepasst werden. Stattdessen werden diese Varianzen von Gut-Teilen mit ins Training des KI-Systems aufgenommen, was den OK-Raum des Systems automatisch um diese Varianzen erweitert.
Überwachte KI-Modelle als Lösung
Wesentlich besser agieren dagegen Modelle mit überwachten KI-Algorithmen, also Supervised AI. Diese Modelle sind grundsätzlich in der Lage, das Problem von zu hohem Pseudoausschuss zu lösen.
Während eine reine Anomalieerkennung jede Abweichung pauschal als Fehler wertet, lernen überwachte KI-Modelle aus annotierten Daten nicht nur, welche Pixel oder Regionen zu Gutteilen gehören, sondern auch, welche zu konkreten Fehlerklassen. Dafür ist menschlicher Input nötig: Fachleute markieren die Defekte in den Bildern und liefern so die entscheidenden Lernsignale für das KI-Training. Auf dieser Basis lernt das KI-Modell, wie die einzelnen Defekte aussehen. Dadurch kann es sehr präzise zwischen tolerierbarer Produktionsvarianz und echten Fehlern unterscheiden, die Erkennungsgenauigkeit erhöht sich und die Pseudoausschussrate sinkt.

Die Krux mit dem Datensatz
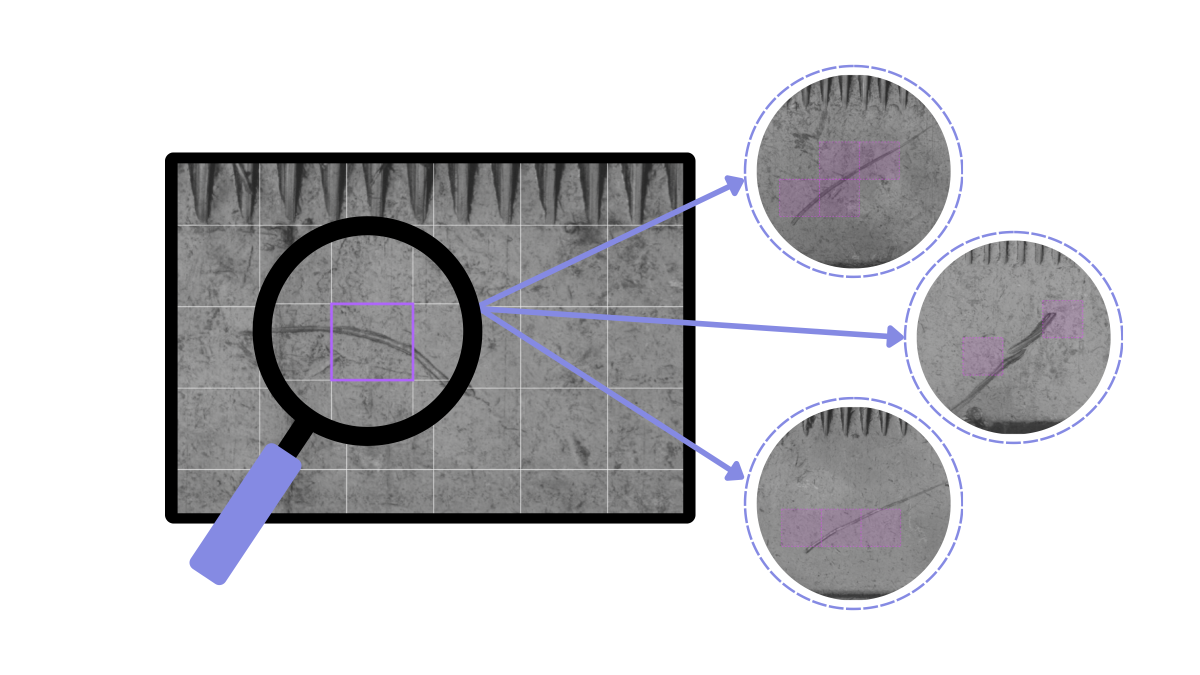
Die Grundvoraussetzung dafür sind allerdings konsistente Daten als Lernsignal für die KI. Ein konsistentes Lernsignal erfordert ein sehr striktes Regime bei der Annotation von Daten als Grundlage für den Lernprozess des KI-Systems. Typischerweise werden Daten, soweit sie nicht synthetisch generiert sind, von Menschen annotiert. Der Mensch bleibt also ein kritischer Faktor – und mit ihm auch die aus der manuellen Inspektion bekannten Probleme wie Subjektivität und Inkonsistenz. So kann beispielsweise ein Kratzer in einem Bauteil als Nicht-OK markiert sein, während ein ähnlicher Kratzer auf anderen Prüfteilen bei der Annotation übersehen wird. Als Folge erhält das KI-System in der Anlernphase bei dieser Fehlstelle kein konstantes Lernsignal, was wiederum eine erhöhte Rate bei Schlupf und Pseudoausschuss nach sich zieht. Auch das beste KI-System bleibt wirkungslos, wenn die Datengrundlage widersprüchlich ist.
Datenkuratierung macht den Unterschied
Entscheidend für die Effizienz eines KI-Systems ist also die Erzeugung eines konsistenten, sauberen Datensatzes. Um diesen kritischen Schritt zu meistern, benötigen Anwender Unterstützung. Hier setzt eine von Maddox AI konzipierte Plattform an. Die Bandbreite ihrer Tools reicht dabei von einfachen Übersichts- und Filtermöglichkeiten bis hin zu KI-basierter Labeling-Unterstützung. Beispielsweise kann man sich eine Auswahl aller Annotationen einer Defektklasse auf einen Blick anzeigen lassen, um leicht überprüfen zu können, ob die Konsistenz innerhalb dieser Fehlerklasse gegeben ist. Alternativ können alle Bilddaten mittels „Similarity Search“ auf visuelle Muster hin durchsucht werden. So werden automatisch Inkonsistenzen in den Annotationen angezeigt, die ein Korrekturvorgang beseitigen kann, anstatt manuell viele Bilder auf mögliche Inkonsistenzen zu suchen. Allen betroffenen Bildern im Datensatz kann dieselbe Aktion zugeordnet werden, beispielsweise dass Kratzer unter zwei Millimeter grundsätzlich ignoriert werden.
Darüber hinaus schlägt das System genau die Bilder in bereits vorhandenen, großen Bildmengen vor, die „interessant“ sind. Der Experte bekommt aus den archivierten Bilddaten von möglicherweise mehreren hunderttausend Bildern eine übersichtliche Auswahl vorgeschlagen, was eine mühsame manuelle Suche erspart. Das Tooling unterstützt also dabei, neue Bilder zu identifizieren, die für die Erklärgenauigkeit des Modells relevant sind.
In der industriellen Qualitätskontrolle ist die Verfügbarkeit von Daten oft ungleich verteilt: Es gibt meist viele fehlerfreie, aber nur wenige defekte Teile. Für ein robustes Modell reicht diese Verteilung jedoch nicht aus. Sollten keine Originalbilder vorhanden sein, kann das Maddox-Tool auch entsprechende Datensätze synthetisch generieren. Oberstes Ziel ist es auch hier, mit einem sauber kuratierten Datensatz die Produktionsvarianz möglichst optimal abzubilden.
Die Maddox-AI-Software vereinfacht das Erstellen konsistenter, hochwertiger Datensätze und ermöglicht es KI-Experten wie auch Fachleuten ohne KI-Hintergrund, Modelle selbstständig zu trainieren und produktiv einzusetzen. Der niedrigschwellige Zugang bindet Domänenwissen direkt ein, beschleunigt Iterationen und macht KI so im Alltag einsatzfähig. Unternehmen werden unabhängiger von knappen Spezialisten, verkürzen die Time-to-Value und erschließen Anwendungsfälle, die zuvor an fehlenden Kapazitäten scheiterten. Ändern sich die Bedingungen in der Produktionslinie – etwa durch neue Defektklassen oder Produktionsvarianten – können Fachleute Anpassungen eigenständig vornehmen und in die Produktion überführen. Diese Möglichkeit der kontinuierlichen Selbstoptimierung erhöht die Erkennungsgenauigkeit fortlaufend und senkt damit Pseudoausschuss und Schlupf.
Was beim Retrofit ersetzt wird
Beim klassischen Retrofit – etwa eines regelbasierten Bildverarbeitungssystems – läuft das in der Produktion installierte Kamerasystem unverändert weiter. Ersetzt wird lediglich die Software. Mit den Annotationstools von Maddox AI entsteht schnell eine saubere Datengrundlage. Durch die intuitive Nutzeroberfläche lassen sich neue Modelle einfach trainieren und in die Produktion überführen. Die gute Datengrundlage steigert die Erkennungsgenauigkeit der Algorithmik und senkt den Pseudoausschuss spürbar. Da die Maddox AI Software Annotationen vereinheitlicht und daher in kurzer Zeit präzise KI-Modelle liefert, arbeitet Maddox AI erfolgsbasiert: Abgerechnet werden nur Implementierungen, die eine zuvor vereinbarte Mindestsenkung des Pseudoausschusses erreichen. Bleibt die vereinbarte Verbesserung aus, fallen keine Kosten an.