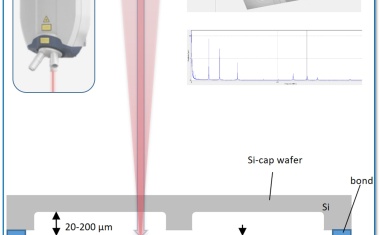
Multisensorik wird noch flexibler
Der Scopecheck FB von Werth Messtechnik steht jetzt wahlweise mit einer, zwei oder drei unabhängigen Sensorachsen zur Verfügung. Die Multisensorik ist integriert und kann daher ohne Einschränkung und ohne zeitaufwändige Sensorwechsel eingesetzt werden.