Nachhaltige Edge-Intelligenz
Künstliche Intelligenz – sowohl Training als auch die eigentliche Inferenz – konnte bisher hauptsächlich für Rechenzentren entwickelt werden. Dieser Trend verändert sich jedoch aktuell. Wenn die Inferenz direkt auf den bildgebenden Geräten selbst stattfinden soll, werden die Dinge interessant. Wie lässt sich eine derart leistungshungrige Technologie außerhalb von großen Rechenzentren in den kleinen ressourcenoptimierten Embedded-Geräten effizient und nachhaltig einsetzen? Es gibt bereits einige funktionierende Ansätze und Lösungen, um Neuronale Netze auf Edge-Geräten effizient zu beschleunigen. Aber nur wenige sind flexibel genug, um mit der schnell fortschreitenden KI-Entwicklung Schritt zu halten.
Vereinfacht ausgedrückt beschreibt der Begriff Edge eine Geräteklasse, die mithilfe von Neuronalen Netzen und Machine-Learning-Algorithmen Inferenzaufgaben am Rande von Netzwerken („on the edge“) lösen kann. Eine Frage, die man sich in diesem Zusammenhang stellen sollte, ist, warum Künstliche Intelligenz (KI) vermehrt in Embedded-Geräten zum Einsatz kommen soll und warum Deep Learning und Deep Neural Networks gerade jetzt in den Fokus der Industrie rücken.
Die Antworten auf diese Frage drehen sich weniger um die KI an sich, sondern um Themen wie Bandbreite, Latenzzeiten, Sicherheit oder dezentrale Datenverarbeitung. Also eher die Kernthemen und Herausforderungen von Industrie-4.0-Anwendungen. Eine wichtige Aufgabe ist es, den inhärenten Wettbewerb um die Bandbreite des gemeinsamen genutzten Kommunikationskanals zu reduzieren, indem große Mengen an Sensor- oder Kameradaten schon auf den Edge-Geräten selbst gefiltert beziehungsweise in verwertbare Informationen gewandelt werden. Die unmittelbare Datenverarbeitung ermöglicht zudem Prozessentscheidungen am Ort der Bildaufnahme ohne die Latenz der Datenkommunikation. Aus technischer oder sicherheitsrelevanter Sicht kann es sogar sein, dass eine zuverlässige und kontinuierliche Kommunikation mit einer zentralen Verarbeitungseinheit, vielleicht sogar in der Cloud, nur schwer möglich oder unerwünscht ist. Eine Kapselung der erworbenen Daten auf Edge-Geräten würde zudem zur Dezentralisierung der Datenspeicherung bzw. deren Verarbeitung beitragen. Demzufolge wären die Daten auch sicherer und weniger anfällig für Angriff von außen.

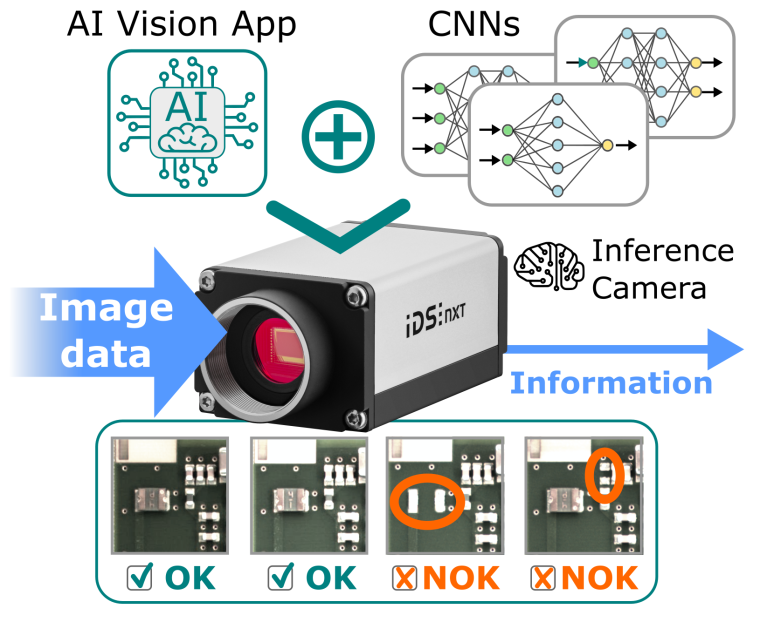
Eine verteilte Systemintelligenz schafft zudem eine klare Trennung auftragsspezifischer Aufgaben. In einer Fabrik kann es hunderte Arbeitsstationen geben, die einen Bildklassifizierungsdienst benötigen, der an jeder Station einen anderen Satz von Objekten analysieren soll. Das Hosten mehrerer Klassifikatoren in der Cloud ist aber mit Kosten verbunden.
Wünschenswert ist eine kostengünstige Lösung, die sämtliche Klassifikatoren in der Cloud trainiert und deren Modelle an die Edge-Geräte sendet, und zwar angepasst an die jeweilige Arbeitsstation. Die Spezialisierung jedes Modells auf eine bestimmte Anwendung ist zudem insgesamt leistungsfähiger als ein Klassifikator, der über alle Arbeitsstationen hinweg Vorhersagen trifft. Zusätzlich senken die einfachen Speziallösungen, im Gegensatz zur Datacenter-Realisierung, auch wertvolle Entwicklungszeit. Dies alles spricht dafür, die Inferenzausführung auf Edge-Geräte auszulagern.
Bei Edge-Geräten dreht sich alles um Effizenz
KI-Inferenzaufgaben auf Edge-Geräten auszuführen ist allerdings nicht trivial. Beim Thema Edge Computing allgemein dreht sich alles um Effizienz. Edge-Geräten stehen meist nur begrenzte Mengen an Rechen-, Speicher- und Energieressourcen zur Verfügung. Berechnungen müssen also sehr effizient erfolgen, sollen aber gleichzeitig hohe Leistungswerte erbringen und das Ganze bei niedriger Latenz – was irgendwie unvereinbar scheint. Mit der Ausführung von neuronalen Netzen (Convolutional Neural Network, CNN) haben wir es dazu noch mit der Königsdisziplin zu tun. Gerade CNNs sind dafür bekannt, dass sie sehr rechenintensiv sind und Milliarden von Berechnungen benötigen, um eine Eingabe zu verarbeiten. Mit Millionen Parametern, welche die CNN-Architektur selbst beschreiben, sind sie prinzipiell kein guter Kandidat für Edge-Computing.
Für den Embedded-Einsatz bieten sich sogenannte parameter-effiziente Netze an, beispielsweise Mobilnet, Efficientnet oder Squeezenet, die wenige Parametern benötigen, um sie zu beschreiben. Das reduziert den Speicherbedarf und die Rechenanforderungen deutlich. Um die Speicheranforderungen weiter zu senken, müssen die Netze komprimiert werden. So lassen sich zum Beispiel unwichtige Parameter nach dem Training durch sogenanntes Pruning entfernen, oder die Anzahl Bits zur Beschreibung der Parameter durch eine Quantisierung reduzieren. Die reduzierte Speichergröße des CNNs wirkt sich zudem positiv auf dessen Verarbeitungszeit aus. Und das führt uns zum letzten Aspekt der Optimierung.
Die richtige Edge-Plattform finden
Trotz parametereffizienter und komprimierter Netzwerke muss immer noch ein Rechensystem verwendet werden, das auf die Architekturen zugeschnitten ist, um die KI on the edge effizient auszuführen. Dazu gilt es zwei grundlegende Systemeigenschaften zu betrachten: Neben der bereits erwähnten Effizienz sollte das System so flexibel sein, auch neue Entwicklungen von CNN-Architekturen zu unterstützen. Das ist wichtig, da gerade im Bereich der KI monatliche neue Architekturen und neue Layer-Typen den Entwicklungs- und Forschungsbereich verlassen. Dinge, die heute aktuell und neu sind, können morgen schon überholt sein.
Welche Plattform-Möglichkeiten gibt es also?
Ein CPU-basiertes System ist am flexibelsten. Allerdings sind CPUs beim Ausführen von CNNs sehr ineffizient und auch nicht sehr stromsparend.
Eine GPU-Plattform hat durch ihre parallel arbeitenden Berechnungseinheiten sehr viel Leistung für das Ausführen von CNNs. Sie sind zwar spezialisierter als CPUs, aber trotzdem noch flexibel. Allerdings sind GPUs sehr energiehungrig und damit für On-the-edge-Anwendungen problematisch.
Die Architektur programmierbarer FPGAs lässt sich im Feld rekonfigurieren und somit gegebenenfalls auf neue CNN-Architekturen anpassen. Durch ihre parallele Arbeitsweise arbeiten FPGAs ebenfalls sehr schnell. Ihre Programmierung setzt aber viel Hardware-Wissen voraus.
Eine vollständige Asic-Lösung ist als maßgeschneiderter integrierter Schaltkreis der offensichtliche Gewinner in Bezug auf Effizienz, da er speziell für das effiziente Ausführen einer bestimmten CNN-Architektur optimiert werden kann. Diese Flexibilität könnte aber ein Problem sein, wenn der Asic neue oder geänderte CNN-Architekturen nicht mehr unterstützt.
Mit den Eigenschaften „hoch performant, flexibel und energieeffizient“ eignen sich FPGAs zum aktuellen Zeitpunkt der KI-Entwicklung also am besten für die CNN-Beschleunigung auf Edge-Geräten. Die Fähigkeit, sie jederzeit zur Laufzeit des Geräts durch ein Update für spezielle Anwendungen oder CNNs anzupassen, macht sie zu einer langfristig funktionierenden und damit industrietauglichen Lösung. Die größte Herausforderung beim Einsatz von FPGAs ist, dass ihre Programmierung sehr aufwändig ist und nur Spezialisten sie bewältigen.
Entwicklungsstrategie
Um Neuronale Netzwerke in einem Vision-Edge-Gerät, etwa den IDS NXT Kameras auszuführen, hat sich der Kamerahersteller für die Entwicklung eines CNN-Beschleunigers auf Basis der FPGA Technologie entschieden. Das Ergebnis nennt das Unternehmen Deep Ocean Core. Um den Umgang mit dem FPGA im späteren Gebrauch jedoch so einfach wie möglich zu halten, sollten nicht mehrere speziell optimierte Konfigurationen für verschiedene CNN-Typen entwickelt werden, sondern eine universell einsetzbare Architektur. Der Beschleuniger kann dadurch jedes CNN ausführen, vorausgesetzt, es besteht aus unterstützten Schichten. Da jedoch alle regulären Schichten, beispielsweise Faltungs-, Additions-, verschiedene Arten von Pooling- oder Squeezing-Excite-Schichten bereits unterstützt werden, ist im Grunde genommen jeder wichtige Schichttyp einsetzbar. Und damit ist das Problem der schwierigen Programmierung komplett beseitigt, weil der Anwender kein spezifisches Wissen haben muss, um eine neue FPGA-Konfiguration zu erzeugen. Durch Firmware Updates der Kamera wird auch der FPGA ständig aktualisiert, um mit den Entwicklungen im CNN-Bereich Schritt zu halten.
FPGA ohne Programmierkenntnisse konfigurieren
Der Beschleuniger benötigt lediglich eine binäre Beschreibung, aus der hervorgeht, aus welchen Schichten sich das CNN zusammensetzt. Dazu ist keine Programmierung notwendig. Jedoch liegt ein Neuronales Netzwerk, das zum Beispiel mit Keras trainiert wurde, in einer speziellen Keras-Hochsprache vor, die der Beschleuniger nicht versteht. Dazu muss es in ein Binärformat übersetzt werden, das einer Art verketteter Liste gleicht. Aus jeder Schicht des CNN wird ein Knotendeskriptor, der jede Schicht genau beschreibt. Am Ende entsteht eine vollständig verkettete Liste des CNN in binärer Darstellung. Der gesamte Übersetzungsprozess wird von einem Tool automatisiert durchgeführt. Auch dazu ist keinerlei Spezialwissen notwendig. Die erzeugte Binärdatei wird nun in den Arbeitsspeicher der Kamera geladen und der FPGA beginnt mit der Verarbeitung. Das CNN läuft nun auf der IDS NXT Kamera.
Das neuronale Netz on the fly wechseln
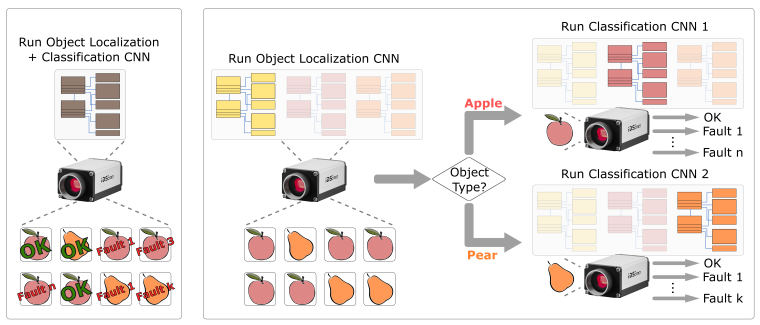
Die Verwendung einer CNN-Repräsentation als verkettete Liste hat klare Vorteile, was die Flexibilität des Beschleunigers angeht. Damit ist es möglich, on the fly zwischen Netzwerken ohne Verzögerung umzuschalten. Im Arbeitsspeicher der Kamera können dazu mehrere Linked List Representations von unterschiedlichen Neuronalen Netzwerken geladen sein. Um ein CNN zur Ausführung auszuwählen, muss der Deep-Ocean-Beschleuniger an den Anfang einer dieser Listen zeigen. Dazu muss lediglich ein Zeigerwert auf einen der Listenspeicher geändert werden. Wir reden hier von einem einfachen Schreibvorgang eines FPGA-Registers, der sich jederzeit schnell durchführen lässt.
Warum dieses schnelle Umschalten von CNN Netzwerken wichtig sein kann, erklärt folgendes Beispiel. Nehmen wir an, der Anwender hat eine Produktionslinie mit zwei Arten von Produkten, deren Qualität inspiziert werden soll. Dazu muss zuerst deren Position erkannt und danach anhand der identifizierten Produktkategorie die Qualität nach produktspezifischen Fehlern klassifiziert werden.
Die Aufgabe ließe sich lösen, indem der Anwender ein großes CNN darauf trainiert, die Objekte zu finden und gleichzeitig zu klassifizieren, indem er jeden einzelnen möglichen Fehlerfall für jede der Produktgruppen vortrainiert. Das ist zwar sehr aufwändig und das Netz würde sehr groß werden und möglicherweise nur langsam arbeiten, könnte aber funktionieren.
Die Schwierigkeit dabei wird sein, eine ausreichend hohe Genauigkeit zu erreichen. Mit der Möglichkeit, das aktive CNN on the fly zu wechseln, kann die Lokalisierung und Klassifizierung der unterschiedlichen Objekte entkoppelt werden. Mit der Folge, dass die einzelnen CNNs einfacher zu trainieren sind. Die Objekterkennung muss lediglich zwei Klassen voneinander unterscheiden und deren Positionen liefern. Zwei weitere Netze werden nur auf die jeweiligen produktspezifischen Eigenschaften und Fehlerklassen trainiert. Je nach lokalisiertem Produkt entscheidet die Kamera-Applikation dann vollautomatisch, welches Klassifikationsnetz aktiviert wird, um auch die jeweilige Produktqualität zu bestimmen.
Durch dieses Vorgehen arbeitet das Edge-Gerät mit relativ einfachen Einzelaufgaben mit wenigen Parametern. Demzufolge sind auch die einzelnen Netze wesentlich kleiner, müssen viel weniger Merkmale differenzieren und arbeiten dadurch deutlich schneller und energieschonender, wodurch sie sich optimal für die Ausführung auf einem Edge-Gerät eignen.
Performant und effizient
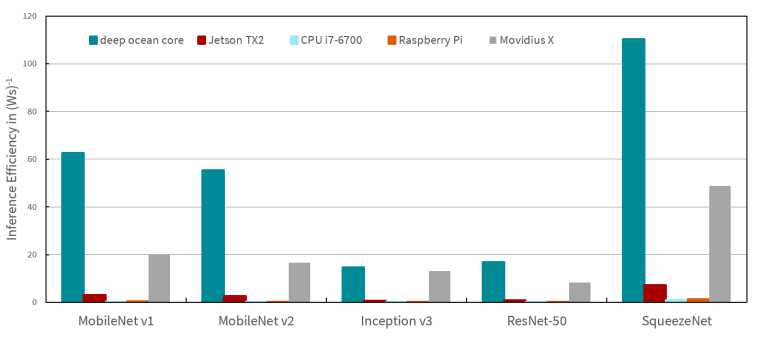
Der FPGA basierte CNN-Beschleuniger arbeitet in den IDS-NXT-Inferenzkameras auf einem Xilinx Zynq Ultrascale SoC mit 64 Compute Cores. Viele bekannte Bildklassifizierungsnetzwerke, wie Mobilenet, Squeezenet oder Efficientnet, erreichen bis zu 67 Frames pro Sekunde. Auch auf Netzwerkfamilien wie Inception oder Resnet, die als zu komplex für Edge-Computing gelten, sind 20 Bilder pro Sekunde möglich, was für viele Anwendungen völlig ausreichend ist. Die FPGA-Implementierung ermöglicht es zudem, die Leistung des Deep-Ocean-Beschleunigers weiterzuentwickeln. Durch Firmware-Updates profitieren davon auch alle sich bereits im Feld befindlichen Kameras.
Noch wichtiger beim Thema Edge-Computing ist jedoch die Leistungseffizienz. Sie gibt an, wie viele Bilder pro Sekunde ein System pro Watt Energie verarbeiten kann. Damit ist die Leistungseffizienz eine gute Messgröße, um verschiedene Edge-Lösungen zu vergleichen.
Niedrige Einstiegshürde für Deep Learning
Um den Umgang mit dem FPGA-basierten CNN-Beschleuniger noch einfacher zu gestalten, bietet IDS eine Inferenzkamera-Komplettlösung an, um die Technologie für jeden einfach zugänglich zu machen. Anwender benötigen zum Trainieren und Ausführen eines neuronalen Netzes weder Fachwissen über Deep Learning noch zu Bildverarbeitung oder Kamera- beziehungsweise FPGA-Programmierung und können sofort mit der KI-basierten Bildverarbeitung beginnen. Einfach zu bedienende Werkzeuge senken die Einstiegshürde, um Inferenzaufgaben in wenigen Minuten zu erstellen und sofort auf einer Kamera auszuführen. Neben der Kamera-Plattform IDS NXT mit dem FPGA-basierten CNN-Beschleuniger Deep Ocean Core gehört noch eine einfach zu bedienende Trainings-Software für neuronale Netze zum Gesamtkonzept. Alle Komponenten entwickelt IDS selbst und konzipiert sie so, dass sie nahtlos zusammenarbeiten. Das vereinfacht die Arbeitsabläufe und macht das Gesamtsystem sehr leistungsfähig.
Nachhaltige Edge-Intelligenz
Jede der im Artikel angesprochenen Möglichkeiten zur Ausführung von Neuronalen Netzen hat individuelle Vor- und Nachteile. Müssen sich Endanwender selbst mit den nötigen Komponenten befassen, um KI für Machine-Vision-Aufgaben zu nutzen, greifen sie gerne zu vollintegrierten KI-Beschleunigern, wie den Intel Movidius. Fertig-Chip-Lösungen arbeiten effizient, ermöglichen Stückpreise, die nur in großen Mengen möglich werden und lassen sich durch eine umfangreiche Dokumentation des Funktionsumfangs schnell und relativ einfach in Systeme integrieren.
Es gibt leider einen Haken: Deren lange Entwicklungszeit ist ein Problem im KI-Umfeld, das jetzt enorm an Fahrt aufgenommen hat und sich täglich verändert. Um heute eine universell und flexibel arbeitende Edge-Intelligenz zu entwickeln, müssen die Systemkomponenten andere Voraussetzungen erfüllen. Eine FPGA-Basis ist die optimale Kombination aus Flexibilität, Performance, Energieeffizienz und Nachhaltigkeit. Denn eine der wichtigsten Anforderungen an ein Industrieprodukt ist seine Industrietauglichkeit, die neben anderen Faktoren durch eine lange Verfügbarkeit und eine einfache und langjährige Wartbarkeit sichergestellt wird.
Autor
Heiko Seitz, Technischer Redakteur
Anbieter
IDS Imaging Development Systems GmbHDimbacher Str. 10
74182 Obersulm
Deutschland





Meist gelesen

Industrielle Qualitätsprüfung mit Contact-Image-Sensoren
Für die Qualitätsprüfung flacher Objekte oder Endlosmaterial sind Contact-Image-Sensoren eine Alternative zu Zeilenkameras. Rauscher erweitert sein Portfolio um Insnex-CIS-Module mit bis zu 3.600 DPI.

Praxisnahe Tests und starke Kundenbindung
Aerotech schafft mit Laserlabor am Standort Fürth zentralen Anlaufpunkt für Applikations- und Entwicklungstests

Sind KIs Jobkiller? Nö! Aber gehypte CEOs vielleicht schon
Die tatsächlichen Produktivitätsgewinne heutiger KIs sind begrenzt. Die eigentliche Gefahr liegt weniger in der Technik als in gehypten Managern. Ein Kommentar.

Warum Logistik über die Wettbewerbsfähigkeit entscheidet
Digitalisierung, Nachhaltigkeit und Resilienz müssen gleichzeitig gelingen – in einer Zeit, in der Kosten steigen und Ressourcen knapp sind. Logistik entscheidet damit über Tempo, Stabilität und Wettbewerbsfähigkeit.

Die Zukunft der Intralogistik
Die Intralogistik befindet sich im Wandel: Der Bedarf an qualifizierten Fachkräften steigt, während gleichzeitig neue Konzepte und Technologien entstehen.