Multikamera-Applikationen in Echtzeit
Hybride Systeme aus FPGAs und CPUs kombinieren Vorteile für notwendigen Durchsatz
Micro-TCA-basierte Plattformen sind prädestiniert für den modularen Aufbau echtzeitfähiger Lösungsplattformen für Multikamera-Applikationen. Hybride Auslegungen kombinieren hierfür FPGAs und CPUs. Solche Plattformen eignen sich immer dann, wenn hohe Datenströme anfallen – wie bei der Inline-Qualitätskontrolle, der 3D-Inspektion oder bei sicherheitsrelevanten Überwachungsfunktionen.
Die gleichzeitige Verarbeitung bildgebender Datenströme mehrerer hochauflösender Kameras erfordert für industrielle Vision-Anwendungen immer häufiger neue Konzepte jenseits des klassischen PC-basierten Ansatzes. Die Herausforderungen an die zu verwendende Hardware potenzieren sich mit steigender Anzahl Kameras und den Echtzeitanforderungen. Hier können FPGAs kombiniert mit CPUs die effiziente Bewältigung komplexer Aufgaben erheblich verbessern. Ein solcher hybrider Ansatz aus FPGAs und CPUs kann die jeweiligen Stärken optimal nutzen, indem er die parallelen Verarbeitungsfähigkeiten und geringen Latenzzeiten von FPGAs mit den vielseitigen und höherschichtigen Verarbeitungsfähigkeiten von CPUs kombiniert.
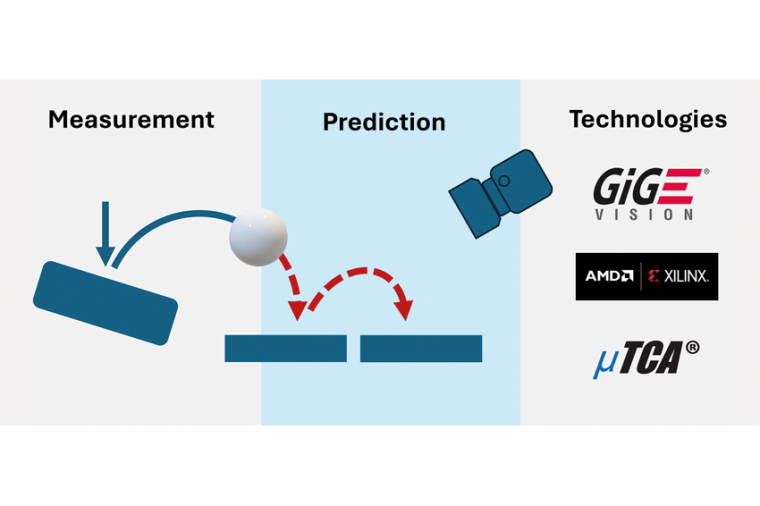

Der Bildverarbeitungs-Workflow
Zum besseren Verständnis ist es hilfreich, sich die typischen Prozessschritte des Bildverarbeitungsworkflow zu verdeutlichen und aufzuzeigen, wie eine effiziente Aufgabenteilung erfolgen kann.
Bilderfassung: Die von gegebenenfalls synchronisierten (zum Beispiel IEEE1588) Kameras erfassten Bilder werden von diesen über Hochgeschwindigkeitsschnittstellen (zum Beispiel Camera Link, CoaXPress, GigE Vision oder USB3 Vision) an einen FPGA übertragen.
FPGA-Verarbeitung: Neben den typischen Schritten wie Rauschunterdrückung, Kontrastverbesserung, grundlegender Merkmalsextraktion wird auch eine Umcodierung des Datenstroms zur universellen Weiterverarbeitung im FPGA vorgenommen (AXI-Stream). Letztere ermöglicht dann im FPGA aufgabenspezifische Verarbeitungsschritte wie bestimmte Echtzeit-Algorithmen zur Fehler- und Mustererkennung oder auch weitergehender Merkmalsextraktion und -qualifizierung. Auch eröffnet der AXI-Stream die Implementierung kundenspezifischer Algorithmen zur Fehler- oder Mustererkennung oder anderer spezifische Aufgaben direkt im FPGA. Neben der Möglichkeit synchronisierter Zeitstempel ermöglicht der FPGA auch das direkte Auslösen zeitsynchronisierter Triggersignale, die zur Steuerung externer Systeme genutzt werden können.
Weitertransport der Daten: Abhängig von der bereits erfolgten Verarbeitung der Rohdaten im FPGA können die Daten zur weiteren Verarbeitung deterministisch an einen oder mehrere andere FPGAs, CPUs oder KI-Beschleuniger-Karten übertragen werden. Dies geschieht in der Regel über nicht-blockierende Hochgeschwindigkeitsverbindungen entweder direkt Punkt-zu-Punkt oder über einen entsprechenden systemimmanenten Switch (PCIe oder ETH) über die System-Backplane.
CPU-Verarbeitung: Aufgaben wie die 3D-Rekonstruktion, komplexe Analysen, maschinelles Lernen und umfassende Entscheidungsfindungen sowie Systemkoordination werden optimal mit einer CPU realisiert. Die CPU ist auch der Aggregierungspunkt für die vorverarbeiteten Daten aus den FPGAs. Bei Bedarf kann eine CPU auch sehr einfach als Schnittstelle zu anderen industriellen Systemen agieren.
Datenausgabe und Steuerung: Am Ende des Workflows steht als letzter Schritt die Datenprotokollierung und -Visualisierung über Benutzeroberflächen zur Überwachung und Ergebniskontrolle. Üblicherweise wird dies ebenfalls mit Hilfe einer CPU-Karte realisiert.
Eine Beispielrechnung
Die Leistungsfähigkeit einer solchen Lösungsplattform lässt sich leicht anhand einer Beispielrechnung veranschaulichen: Eine einzige 10GigE-Vision-RGB-Kamera mit einer Auflösung von 2.440 x 2.048 px generiert bei 24 Bit pro Pixel einen Bildrahmen (Frame) von rund 120 Mbit. Bei Verwendung eines Bayer-Filters mit 8 Bit pro Pixel reduziert sich die Größe des Bildrahmens auf etwa 40 Mbit.
Unter der Annahme von 150 Frames pro Sekunden führt dies ohne Filter zu einem Datenstrom von 18,6 Gbps, mit Bayer-Filter zu immerhin 6,2 Gbps. Dieses Datenvolumen skaliert mit der Anzahl verwendeter Kameras: Bei vier Kameras würden mit dem vierfachen Datenstrom bereits 74,4 Gbps beziehungsweise 24,8 Gbps anfallen.
Es ist jedoch zu beachten, dass der eingesetzte FPGA die Rohdaten unkomprimiert verarbeitet, das heißt unabhängig von der verwendeten Datenreduktion findet eingangsseitig im FPGA eine Dekomprimierung (in unserem Beispiel die Anwendung eines De-Bayer-Filters) statt. Somit muss der FPGA die vollen 4 x 18,6 Gbps verarbeiten.
Wie lässt sich aber ein solcher hybrider Ansatz aus FPGAs und klassischen CPUs für den Anwender praxistauglich umsetzen?
Technologie und Komponenten
Offene und Systemstandards für modulare Backplane-Systeme wie Micro-TCA der PICMG sowie ergänzende Spezifikationen der Vita bieten einen sehr hohen Modularitätsgrad. Gleichzeitig können über Highspeed-Backplanes enorme Datenmengen flexibel zwischen allen Steckkarten des Systems übertragen werden. Aufgrund der Modularität kann jedes System bedarfsgerecht mit FPGA- und CPU-Boards sowie KI-Beschleunigern ergänzt werden. Selbstverständlich müssen hierfür solche Systeme auch eine hochpräzise Synchronisation aller angeschlossenen Kameras gewährleisten, zum Beispiel mittels IEEE1588. Nur dann werden sie zur optimalen Lösung für die Bildverarbeitung bei hohen Bildwiederholungsraten und hohen Bildauflösungen in Echtzeit.
Bilderfassung
Zu empfehlen sind auch Systemkonfigurationen, die kamera- und anwendungsunabhängig konzipiert und damit auch auf die Unterstützung der verschiedenen High-End-Kamera-Schnittstellen ausgerichtet sind. Nur so kann eine solche Lösungsplattform schließlich an unterschiedliche Applikationsanforderungen einfach angepasst werden. Hardwareseitig ist dies durch den Einsatz von modularen, auf dem gleichnamigen offenen Vita-Standard beruhenden FPGA Mezzanine Cards (FMC/FMC+) realisierbar, die auf einem FPGA-basierten Carrier montiert werden. Diese Kartenkombination kann innerhalb eines Micro-TCA-Systems mehrfach – bis zu zwölfmal - vorhanden sein. Je nach erforderlichen Kameraschnittstellen und Bandbreitenanforderungen kann ein FPGA-basiertes Carrier unterschiedliche FMCs aufnehmen. Unterstützt diese Kombination beispielsweise den GigEVision-Standard für Kameras mit bis zu 40 GigE, lassen sich so pro FPGA-Trägerkarte bis zu 4 x 10 GigE- oder 2 x 40 GigE-Kameras anschließen. Es sind aber auch Lösungen für 1 x 100 GigE-Interface umsetzbar. Andere Kameraschnittstellen wie CoaXPress oder PCIe sind selbstverständlich ebenfalls möglich. Vorteilhaft ist es bei einem so hohen Modularitätsgrad, dass solche Lösungen auch einen geschwindigkeitsunabhängigen GigEVision-Stack des Hardwareherstellers lizenzfrei integrieren, um einen reibungslosen Datenaustausch zwischen Kameras und FPGA-Boards zu gewährleisten. Der herstellerseitige GigEVision-Stack sollte zudem eine GenICam-Schnittstelle zur Konfiguration der angeschlossenen Kameras beinhalten.
Diese hohe Leistungsfähigkeit einer einzigen FPGA-Karte (siehe Beispielrechnung) gepaart mit der Möglichkeit, diese mehrfach in eine Micro-TCA-Plattform in Kombination mit CPU-Karten zu integrieren, unterstreicht das Leistungsvermögen eines solchen Ansatzes, was ihn für den Einsatz in Highend-Multicam-Applikationen prädestiniert. N.A.T. ist ein Hersteller, der mit seiner NAT-Vision-Plattform eine entsprechende Lösung geschaffen hat. Sie verfügt in der einfachen Ausstattung über an einem FPGA angeschlossene 1/10 GbE-Schnittstellen, das heißt die gleichzeitige Verarbeitung von bis zu vier Kameras ist immer gegeben. Durch mehrfaches Einfügen weiterer FPGA-Karten in das System kann die Anzahl anschließbarer Kameras entsprechend skaliert werden. Über die optionalen Uplinks des systemimmanenten Switches stehen natürlich auch Schnittstellen höherer Bandbreite zur Verfügung.
Die Technik im Detail
NAT-Vision nutzt die leistungsstarken Xilinx Ultrascale+ FPGAs für das Preprocessing und anspruchsvolle Aufgaben in Vision-Anwendungen. Dazu zählen Deep-Learning-basierte Fehlererkennung, 3D-Bildrekonstruktion und Mustererkennung. Die Programmierung erfolgt über Hardware-Beschreibungssprachen wie VHDL oder Verilog sowie C/C++ mit High-Level-Synthese (HLS), was Entwicklern Flexibilität bietet. Verschiedene FPGA-Karten aus dem N.A.T.-Portfolio stehen zur Auswahl, wobei die kleinsten Konfigurationen die eingebetteten ARM Cores als CPU-Alternative nutzen. Die Karten werden mit einem kompletten Linux BSP für den direkten Einstieg in die Entwicklung geliefert und ermöglichen die parallele Echtzeitverarbeitung großer Datenmengen.
Beim Datenweitertransport profitiert NAT-Vision von der modularen, ausfallsicheren Bauweise des Micro-TCA-Standards. Die Plattformen unterstützen PCIe (Gen4) für schnelle Datenströme und bieten verschiedene Gehäuseoptionen für Systeme mit 1 bis 12 Karten. Vollredundante Systeme, wie sie von High-End-Anwendungen im Telekom-, Forschungs- und Industriebereich bekannt sind, sind ebenfalls möglich. Integrierte Uplink-Schnittstellen ermöglichen die Weiterleitung großer Datenmengen mit bis zu 2 x 100 Gbps. Die Zeitsynchronisation wird über ein zentrales Clock-Modul sichergestellt.
Für erweiterte Prozessressourcen stehen verschiedene CPU-Karten basierend auf Intel-X86 oder NXP-Layerscape zur Verfügung. Diese Karten können die von den FPGAs vorverarbeiteten Daten für weiterführende Verarbeitungen übernehmen, zum Beispiel maschinelles Lernen und komplexe Entscheidungsfindung. Die Plattform wird mit vorinstalliertem Linux und Beispielanwendungen geliefert.
Die NAT-Vision-Plattform kann zudem mit standardisierten I/O-Schnittstellen ausgestattet und für Industriestandards wie EtherCat erweitert werden. Dank Micro-TCA können entsprechende I/O-Karten einfach integriert werden - auch von Drittanbietern.
Fazit
NAT-Vision ist eine High-End-Plattform für industrielle Bildverarbeitung, die auf offenen PICMG-Industriestandards basiert und die Integration von Multikamera-Setups mit FPGA- und CPU-Verarbeitung in industriellen Echtzeit-Bildverarbeitungsanwendungen ermöglicht und eine robuste und flexible Lösung für anspruchsvolle Aufgaben bietet.
Diese Architektur nutzt dabei die parallele Verarbeitungsleistung und geringe Latenz von FPGAs mit den fortschrittlichen Verarbeitungsmöglichkeiten und der Flexibilität von CPUs. Ein solches System kann die strengen Anforderungen der modernen Fertigung erfüllen und gewährleistet hohe Qualität, Effizienz und Innovation. Dieser hybride Ansatz ist ideal für Anwendungen in der Qualitätskontrolle, der Automatisierung, der 3D-Inspektion etc. und bietet erhebliche Vorteile in Bezug auf Geschwindigkeit, Genauigkeit und Skalierbarkeit.
Autoren
Heiko Körte, VP, Director Sales & Marketing bei N.A.T. Europe
Herbert Erd, Business Development Manager bei N.A.T. Europe
Anbieter
Gesellschaft für Netzwerk- und Automatisierungs-Technologie mbH (N.A.T.)Konrad-Zuse-Platz 9
53227 Bonn
Deutschland






Meist gelesen

Supercaps: Die bessere Alternative zur Batterie?
Bei welchen Anwendungen liegen Supercaps vorn und was sind deren Vorteile?

Intelligente Greiflösungen für die Automation von morgen
Mechatronische Systeme für maximale Bewegungsfreiheit, präzise Steuerung und hohe Sicherheit in anspruchsvollen Automatisierungsprozessen.

Eine neue Generation Ringlichter
High-Performance-Ringbeleuchtungen mit anpassbarer Lichtcharakteristik

Warum Autovimation der Exaktera-Gruppe beitrat
Peter Neuhaus erläutert die Beweggründe für den Verkauf von Autovimation an Exaktera. Im Vordergrund stand die strategische Weiterentwicklung durch internationale Vertriebsstrukturen und zusätzliche Marketingressourcen.

Revolutioniert der DCC die Messtechnik?
Digitaler Kalibrierschein (DCC) für
Mehrkomponentenaufnehmer